C.R.I.S.P
githubCRISP — The missing layer between vibe coding and building something people actually want.
CRISP — The Mileva Method
![]()
![]()
A BA/PM framework for AI implementors. Go from vague client brief to Claude Code-ready spec — without building the wrong thing.
Most AI implementations fail before a single line of code is written. Not because the model was wrong. Not because the tools weren’t good enough. Because nobody defined the problem. Nobody measured the baseline. Nobody asked why before asking how.
You’re an AI implementor. You know how to build. You probably even know which tools to use. What you might not have — yet — is the methodology to make sure you’re building the right thing.
This is that methodology.
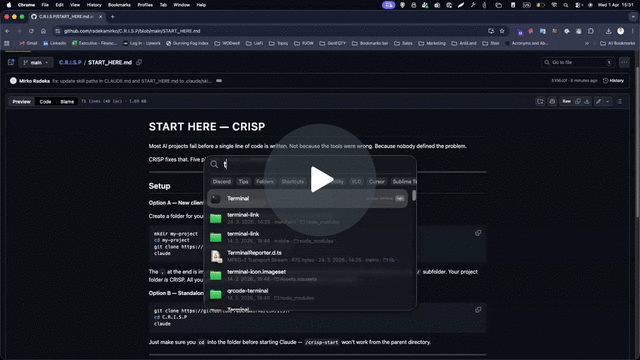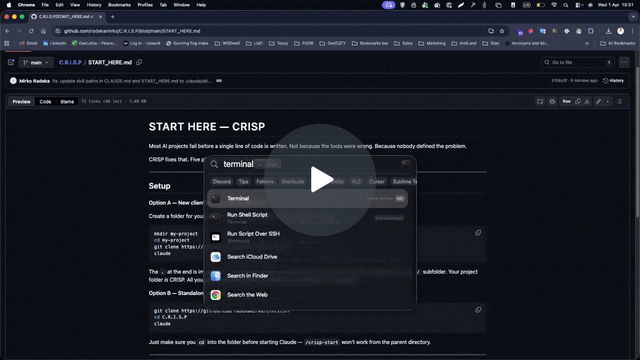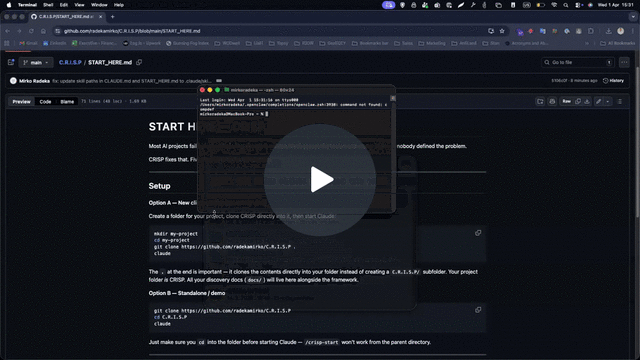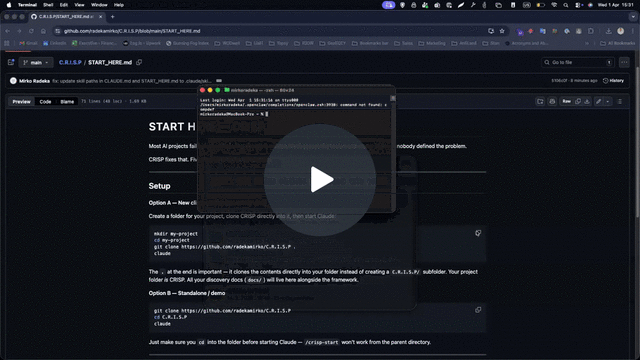
→ START HERE
What is CRISP?
CRISP is an open-source AI project management framework for builders, consultants, and AI agencies. It’s a structured 5-phase methodology that takes you from a vague client request to a fully specced, Claude Code-ready implementation brief — before a single line of code gets written.
Built for:
- AI agency owners running client implementations
- Solo builders using Claude Code, Cursor, or similar agentic tools
- Consultants who need a repeatable discovery-to-spec process
- Product managers working on AI-native products
| Phase | Name | What it does |
|---|---|---|
| C | Clarify | Problem definition, painkiller test, magic wand, constraints, buy vs build, market research — global + regional/local competitor pass (external), value proposition canvas (external), SWOT (external), Go/No-Go |
| R | Results | Stakeholder register + HITL zones (stakeholder-register.md), baseline measurements + success targets (success-metrics.md), tradeoff negotiation |
| I | Investigate | Process mapping (existing or greenfield), user journey maps per system user type, UX discovery (external UI/Mobile/Web), project goals |
| S | Spec | UX/design system, tech stack with pinned versions + NFRs, API key security rules, Bearer security scanning on every PR, initial backlog, assumptions log, risk assessment, HVLE MVP prioritization, AI architecture, sprint-specific open questions, CLAUDE.md, sprint planning, quality gates |
| P | Prove | Did the needle move? Validate against Phase R baseline. |
What’s new in V2
V2 makes CRISP a system, not a collection of prompts. Everything that was previously reliant on discipline is now enforced by structure.
/crisp-orchestrator — new recommended entry point
Replaces the manual “which phase am I on?” problem. Detects docs/crisp-state.json, reports current phase and open questions, routes automatically. Works for new projects and resumption.
crisp-state.json — machine-readable project state
One JSON file in docs/ updated at the end of each phase. Every phase reads it first; every phase writes to it on exit. Claude stops re-interpreting markdown it half-remembered from Phase C when it’s in Phase S.
New mandatory Phase S outputs
- Logging spec (
docs/logging-spec.md) — log levels, PII rules, format, destination. Mandatory, not optional. - Bearer security scanning — Critical/High findings block PR merge. Enforced as a hard gate, not a suggestion.
- Analytics spec (
docs/analytics-spec.md) — GA4 event map tied directly to Phase R success metrics. External UI products only. - Landing page brief (
docs/landing-page-brief.md) — compiled from VPC, market research, UX discovery. For external products, landing page build is MVP-tagged — not a post-launch afterthought. - Agent security spec (
docs/agent-security.md) — AIUC-1-aligned. Mandatory when an agent is in scope. Covers identity/permissions, data handling, failure modes. - Progress report (
docs/progress-report.md) — handoff artifact for clients and continuity across sessions.
Improved Phase S elicitation
- OSS library research — structured GitHub evaluation for every open source dependency before committing. Stars, last commit, license, alternatives rejected with reason.
- Data mapping elicitation — mandatory section in Phase I/S for features involving structured data extraction or transformation. Source → field mapping → DB schema → edge cases.
- Spec→Sprint transition — Phase S now explicitly tells you to say “Start Sprint 1.” No mode switching, no new setup.
Decision log across all phases
docs/decisions.md — every key decision logged with rationale and what was rejected. Auditable. Protects you when client asks “why did you build it this way?”
Memory ownership question
New field in Phase C (problem-statement.md) and Phase S tech stack: does the client require portability of agent memory across platforms? Surfaces before the contract is signed.
Backward compatibility
Nothing breaks. /crisp-start still works. All phase skills behave exactly as before. If no crisp-state.json exists, every phase falls back gracefully. V2 adds structure on top — it doesn’t remove anything.
Why CRISP exists
Every AI project failure I’ve seen had the same root cause.
Builder gets a brief → skips straight to the stack → builds something technically impressive → delivers it → client says “this isn’t what I meant.”
Six weeks. Wasted.
The gap isn’t in the build. It’s in everything before it. CRISP fills that gap with a repeatable, client-tested process — from problem definition to sprint-ready AI specs.
The CRISP principles
Elicit, don’t interrogate. Every question in CRISP follows the same pattern: pre-fill from what you already know, present a hypothesis, let the client correct. People react better than they originate. Corrections surface real intent faster than open questions.
Every document has an upstream source. Nothing is invented twice. Every deliverable is derived from prior phase outputs — not created from scratch. The data pipeline is explicit: you know exactly where each field comes from.
Pre-fill synthesis, elicit discovery. Documents that compile prior decisions are pre-filled and confirmed. Documents that surface new information (stakeholder impacts, hidden risks, unstated goals) get active elicitation moves before confirmation.
No spec = no build. Claude Code never touches a sprint without a locked AI Spec. Every open question in the spec must be resolved before the sprint starts. A spec with unanswered questions is a wishlist, not a brief.
Version everything. Claude defaults to its training data. Pinned versions in the tech stack table — and version rules in CLAUDE.md — are the only way to prevent silent drift.
Security is not optional. API keys never touch the client. All 3rd party credentials stay server-side. Bearer runs on every PR — Critical/High findings block merge. These rules ship in every project’s CLAUDE.md from day one.
How to use
- Drop the
/.claude/skillsfolder into your Claude Code project - Run
/crisp-orchestratorto start a new project or resume an existing one — detects where you are automatically - Use
/templatesas your deliverable starting points — fill outputs intodocs/in your project, never overwrite the blank templates - Run phases in order — do not skip
- Check the exit checklist before moving to the next phase
- Write one AI Spec per sprint before building anything
- After Phase S: just say “Start Sprint 1” — Claude Code reads the AI Spec and starts building. No new setup needed.
How it connects
Every phase feeds the next. Nothing lives in isolation.
C — Clarify
problem-statement ─────────────────────────────────────────────────────────┐
buy-vs-build-matrix ───────────────────────────────────────────────────┐ │
market-research (ext) ─────────────────────────────────────────────┐ │ │
value-proposition-canvas (ext) ────────────────────────────────┐ │ │ │
swot (ext) ─────────────────────────────────────────────────┐ │ │ │ │
│ │ │ │ │
R — Results │ │ │ │ │
stakeholder-register ───────────────────────────────────┐ │ │ │ │ │
(HITL zones) │ │ │ │ │ │
success-metrics ─────────────────────────────────────┐ │ │ │ │ │ │
(baselines + targets + second-order effects) │ │ │ │ │ │ │
│ │ │ │ │ │ │
I — Investigate │ │ │ │ │ │ │
process-flow ──────────────────────────────────────┐ │ │ │ │ │ │ │
user-journey-map (per system user type) ────────┐ │ │ │ │ │ │ │ │
project-goals ───────────────────────────────┐ │ │ │ │ │ │ │ │ │
ux-discovery (ext UI/Mobile/Web) ──────────┐ │ │ │ │ │ │ │ │ │ │
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
S — Spec
design-system + ux-spec (from ux-discovery + user-journey-map)
tech stack — pinned versions + NFRs
initial-backlog (epics from journey stages, linked to goals)
assumptions-log (scanned from all prior docs)
risk-assessment (from SWOT + constraints + HITL zones)
mvp-prioritization — HVLE scoring, dependency map, MVP line (live client conversation)
ai-spec per sprint (pre-filled from docs/, open questions generated + resolved)
CLAUDE.md (compiled from everything — pinned versions, NFRs, output manifest)
sprint-plan (sequenced by MVP tags + dependency map)File structure
crisp/
├── START_HERE.md — start here (human-readable + paste-to-Claude entry point)
├── CLAUDE.md — master CLAUDE.md template (compile per project)
├── .claude/skills/
│ ├── crisp-start/SKILL.md — /crisp-start entry point (legacy — new projects only)
│ ├── crisp-orchestrator/SKILL.md — /crisp-orchestrator recommended entry point (new + resume)
│ ├── phase1-clarify/
│ │ ├── SKILL.md — C: problem definition, elicitation moves, VPC, Go/No-Go
│ │ ├── market-research.md — C: TAM, competitor map, review mining, USP gap (external only)
│ │ └── swot.md — C: pre-filled SWOT, client confirms (external only)
│ ├── phase2-results/
│ │ └── SKILL.md — R: stakeholder register (HITL zones), success metrics & baselines (separate docs)
│ ├── phase3-investigate/
│ │ └── SKILL.md — I: process mapping, user journey maps (per system user type),
│ │ UX discovery (3A–3E), project goals (pre-fill + elicit)
│ ├── phase4-spec/
│ │ ├── SKILL.md — S: full spec process, NFRs, pinned versions, HVLE conversation,
│ │ │ AI Spec open questions, sprint planning, quality gates
│ │ └── mvp-prioritization.md — S: HVLE scoring logic, business value criteria, dependency overrides
│ └── phase5-prove/
│ └── SKILL.md — P: success validation against Phase R baseline
└── templates/
├── problem-statement.md — C: one-sentence problem + constraints + NFRs (appended in 4B) + Go/No-Go
├── buy-vs-build-matrix.md — C: evaluate existing tools before committing to build
├── value-proposition-canvas.md — C: external products only — pre-filled from problem-statement + market-research
├── market-research.md — C: TAM, competitors, feature standards, review insights, USP
├── swot.md — C: strengths, weaknesses, opportunities, threats
├── stakeholder-register.md — R: who is impacted, how, HITL zones
├── success-metrics.md — R: baseline measurements, success targets, second-order effects
├── user-journey-map.md — I: per system user type — steps, needs, feelings, pain points, delights
├── process-flow.md — I: step-by-step process map
├── project-goals.md — I: goals (incl. elicited), non-goals, success criteria
├── ux-discovery.md — I: audience mental models, visual direction, navigation, high-stakes screens
├── design-system.md — S: design philosophy, cognitive UX principles, color/type/motion
├── ux-spec.md — S: sitemap + flow specs + screen specs with cognitive UX checklists
├── initial-backlog.md — S: epics linked to goals, user stories with MVP tags
├── mvp-prioritization.md — S: HVLE scoring table, weighted criteria, dependency map, MVP line
├── assumptions-log.md — S: what was treated as true — surfaced and rated by risk
├── risk-assessment.md — S: what could go wrong, likelihood, mitigation, HITL zones
├── sprint-plan.md — S: sprint sequencing from MVP tags + dependency map
├── ai-spec.md — S: per-sprint brief — pre-filled, open questions, version deps, locked before build
├── agent-skill.md — S: template for each project agent SKILL.md
├── logging-spec.md — S: log levels, PII rules, format, destination, alerting (mandatory)
├── analytics-spec.md — S: GA4 event map, conversion goals, PII rules, sprint gates (external UI only)
├── landing-page-brief.md — S: hero copy, sections, CTAs, visual direction (external products — MVP)
├── crisp-state.json — auto-updated by each phase — project state contract
├── decisions.md — C/R/I/S: decision log across all phases
├── agent-security.md — S: agent identity/permissions, data handling, failure modes (when agent in scope)
├── progress-report.md — any phase: status summary, decisions, open questions, next step
├── data-mapping.md — I/S: structured data extraction field mapping, edge cases, validation
└── CLAUDE.md — S: compiled project context — pinned versions, NFRs, output manifestOutput convention: blank templates live in
/templates/. Filled project outputs live in[project]/docs/. Never overwrite blank templates.
Built by Mileva
CRISP is the methodology behind Mileva — an AI automation agency that builds workflow systems replacing entire operational teams.
If you’re a business owner looking to implement AI without wasting six weeks building the wrong thing, or an agency that wants to productise your discovery process — mileva.io is where this gets applied in the real world.
Questions, PRs, or war stories from using CRISP in the wild: open an issue or find me on X @radekamirko.
Want to contribute? Read CONTRIBUTING.md first.
Outcome first. Always.